
Hi everyone,
I would like to share some basic patch diffing in this post. why patch diffing is important because it helps you to analyze the different between two binary much faster.
As we know that a binary patch is released by the vendor to fix specific vulnerability regularly in their product. We can use binary diffing tools to locate where the update in the binary to understand what is the vulnerability thus help us (malware developer) to create the exploit
BinDiff
BinDiff tools offers integration capability with IDA for binary diffing functionality. You can download it from https://www.zynamics.com/bindiff.html.

Lets do simple diffing. I have two C applications with the code below
Vulnerable Application Code
#include <iostream>
#include <stdio.h>
using namespace std;
void vulnerable_function() {
int i = 1;
if (i == 1) {
if (i > 0) {
printf("This is unpatched software \n");
}
}
}
int main()
{
printf("This is a small application just to show how patch diffing works\n");
vulnerable_function();
}
Patched application code
#include <iostream>
#include <stdio.h>
using namespace std;
void patched_function() {
printf("Nothing is here in patched_function");
}
void vulnerable_function() {
if (1 == 2) {
printf("Nothing is here");
patched_function();
}
else {
for (int ii = 0; ii < 10; ii++) {
int i = 0;
while (i < 10) {
printf("Fixed Process \n");
i++;
}
}
}
}
int main()
{
printf("This is a small application just to show how patch diffing works\n");
vulnerable_function();
}
In order to start diffing, You need to load the first IDA DB to IDA. Then you have to click on the BinDiff on IDA menu to load the second IDA DB
Once both DB are loaded then you can see additional tab come out in IDA

Secondary Unmatched
Subview contains functions that are in the diffed database but were not associated to any functions in the first

Primary Unmatched
The first one displays functions that are contained in the currently open database and were not associated to any function of the diffed database

The meaning of the columns is as follows:
EA
The effective address of the function that is not associated with any other function.
Name
The name of the function that is not associated with any other function.
Basic Blocks, Instructions, Edges
The number of code blocks, instructions and edges in the flow graph in this function. These can be used to identify similar functions manually.
Matched Function

The columns have the following meaning:
Similarity
A value between zero and one indicating how similar two matched functions are. A value of exactly one means the two functions are identical (in regard to their instructions, not their memory addresses).
Values less than one mean the function has changed parts. Please note that BinDiff only considers basic blocks, edges and mnemonics for calculating similarity values. In particular, instructions may differ in their operands, immediate values and addresses and will still be considered equal if the mnemonics match.
Confidence
A value between zero and one indicating the confidence of the similarity score. Note that this value represents the calculated confidence score for the matching algorithms that are enabled in the configuration file.
It is possible to get a high similarity match with a small confidence score or vice versa. This simply means that a weak algorithm has found a good match or a good algorithm has found a weak match.
Change
This column characterizes the difference between the two matched functions. There can be any combination of the following change types, indicated by single letters:
- Graph (G): there have been structural changes in the function. Either the number of basic blocks or the number of edges differs or unmatched edges exist.
- Instruction (I): either the number of instructions differs or at least one mnemonic has changed.
- Jump (J): indicates a branch inversion.
- Entrypoint (E): the entry point basic blocks have not been matched or are different.
- Loop (L): the number of loops has changed.
- Call (C): at least one of the call targets hasn’t been matched.
This is our application different

Based on the above we can see that vulnerable there is change around the vulnerable_function(void). We can see the details by right clicking on the suspected function and view context in call graph
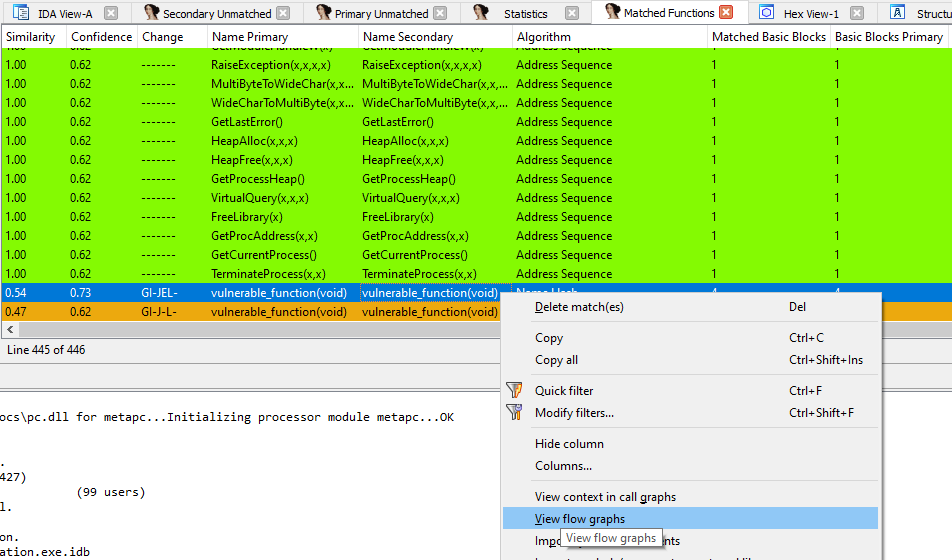
The Flow Graph Comparison

The block with color green means they are both identical between the primary and secondary The nodes in green indicate basic blocks that have identical instruction mnemonics in both executables (although operands to individual assembly instructions might have changed).
The red nodes indicate basic blocks to which our comparison algorithms were unable to find equivalents.
A third category, yellow nodes, indicates nodes for which the algorithms could find equivalents, but which had some instructions changed between versions.
By the information above, We can conclude what is the change or what vulnerability has been patched thus we can develop the exploit.
