Hi Guys,
I want to share a tutorial on how to reconstruct import table of a PE. Basically there is no magic thing here. Why do you need to repair import table of a PE? There are some reasons of it but the one that I want to share in this tutorial is caused by PE packing process.
What is PE Packer ?
In essence, packers are tools that are used to compress a PEfile. This primarily allows the person running the tool to reduce the size ofthe file. As an added benefit, since the file is compressed, it will alsotypically thwart many reverse engineers from analyzing the code statically ( without running it).
Basically packer will encrypt or compress your original PE and put it into a new PE called unpacker stub where the encrypted and compressed of original PE become raw data that will be put into data section in unpacker stub. When the unpacker stub has done its decompression and decrypting the raw data, the stub hand over the new entry point to the new PE in the memory

Packed PE Characteristic
As mentioned above that when the PE is packed then it will be quite hard for the analyst to do reverse engineering without running the PE. There are many charachteristic of an PE that has been packed but i will focuse on the import table. We can see that the Import Table is very much less compared to the original one.
For example like below application
Original version
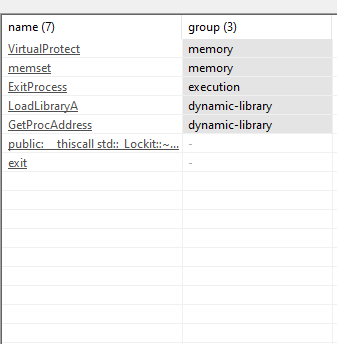
We can see all the import table that is used by the application to run

Packed Version
The import table is much less. We know that a small normal application would import much more then this list
So the steps to reconstruct the import table is, You need to run the application in the debugger like IDA or x86Dbg. I will showcase the steps with IDA debugger like below steps
First you should open PE with IDA.

What IDA can read is basically the unpacker stub. Here we should be able to identify when the unpacker stub hand over the new entry point to the original file. We can use the function available in IDA using Flow Chart
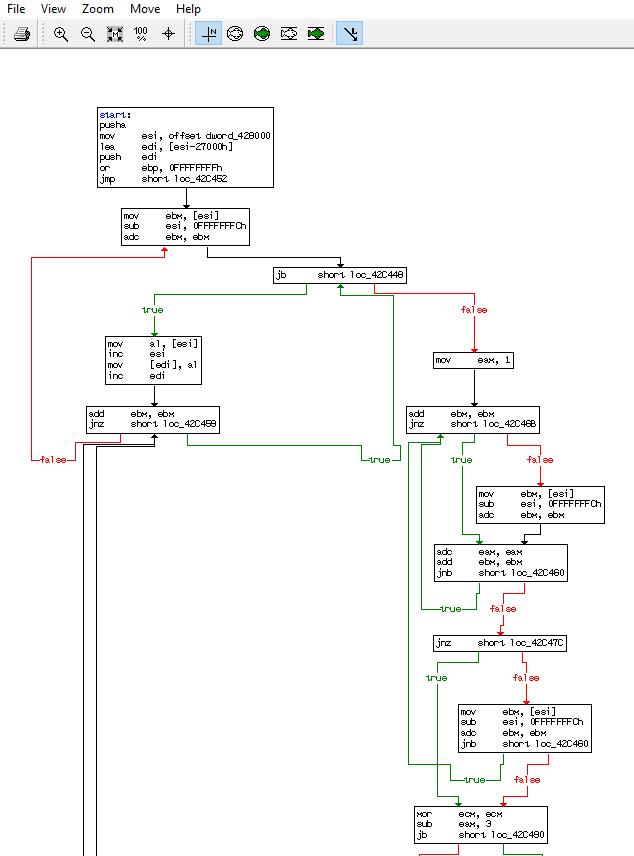
We can gather who is the decryption and encryption flow with the flow chart. but the most important things here is we can see where the stub will hand over the entry point to the new PE after all the decyrption and decmpression process has done

We can see from the flow chart the flow will end at unk_411659. With this information then basically we can know see where the unpacker stub will assign new entry point but since it is static analysis then the new address for the new entry point has not been known.
Now in order to reconstruct the import table, we need to run the application so we can gather all the application information in the memory. We can set our break point in the the last function to pause the application before entering the real application. it is good to set break point here because whenever you analyzing malware then the malware is not run yet.

Dump the Process
As you know that when we do break point just before the unpacker stup hand over the new Entry point to the original application, the original application is ready like a normal PE in the memory to be run and already in full state in memory. We need to dump all information from memory to local file for further static file analyses.
We can dump it using the help of application PETools. Select your process and right click on it and dump full. Save the exe into new folder.

Scylla Reconstructor
Now we are in the phase of to reconstruct the import table using the help of Scylla application. When your application run in the debugging mode under IDA and also being paused due to the break point then the next steps is to attach scylla into your application process in order to read the application from the memory.
After you run Scylla then you can select the application process from the list higlighted below. You should run Scylla with administrator privilege
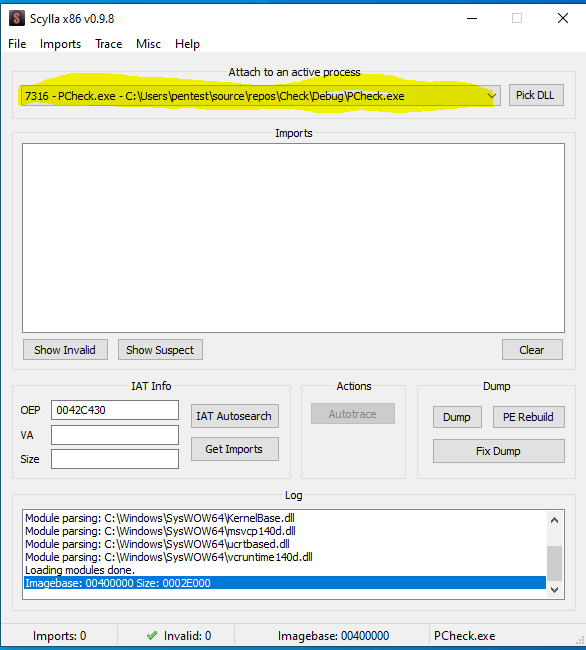
After you select the process then you need to press button IAT Autosearch and press Get Imports to get the list of Import table.

To confirm the import table address is correct then we can check the address gathered in Scylla and IDA. Lets check the below address in IDA
We use go address or pressing “g” in IDA to go to specific address
Lets go the Virtual Address 00426000 in IDA

IDA will jump into the memory we define like below. There is nothing interesting here because IDA recognize this as Data Segments.

We can analyze more by changing the data into code using “C” key to convert Data into Code or “D” to convert Code into Data. You can press C one time here and IDA will remind to for the action. Just press Yes

the data has now changed into code.
Press “G” again to jump again into the Virtual Address 00426000
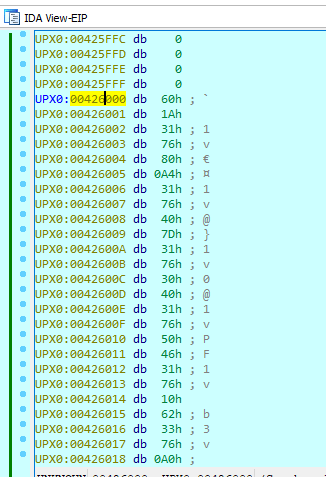
Not interesting yet ? Now lets play by converting it back to data by pressing D. After several times pressing D then we can see something interesting come out

The import table is now showing. Lets compare it with Scylla

We can now confirm that Scylla has properly identified the import table
Now the next steps is to fix our Dump that we have done before. in that dump the import table has not been identified as below

Now press Fix Dump from Scylla and select the file that we dumped using PETools.

We can now see that the PE import table has been reconstructed. We can see all the import table can be identified

